
Analyser des données en utilisant les arbres décisionnels et l'algorithme Random forest
Chaque partition est choisie en sélectionnant le meilleur partitionnement parmi un ensemble de partitionnements possibles, afin de maximiser le gain d'information à chaque nœud de l'arbre. Le gain d'information est lié à l'impureté du nœud, qui mesure l'homogénéité des libellés à un nœud donné.
L'implémentation actuelle fournit deux mesures d'impureté pour la classification :
- L'index de Gini
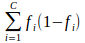
- Entropie
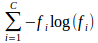 où fi est la fréquence du label i à un nœud donné.
où fi est la fréquence du label i à un nœud donné.
Afin d'être partitionnée, chaque attribut continu doit être discrétisé. Le nombre de boîtes de chaque attribut doit être géré par le paramètre Max Bins. Augmenter la valeur de ce paramètre permet à l'algorithme de prendre en considération davantage de candidat pour le partitionnement et de prendre des décisions plus fines. Cependant, cela augmente les besoins en calculs. La construction de l'arbre de décision s'arrête dès que l'une des conditions suivantes est respectée :
- La profondeur du nœud est égale à la profondeur maximale d'un arbre. Les arbres de décisions plus profonds sont plus expressifs mais ils sont également plus consommateurs en ressources et sujets au sur-apprentissage.
- Aucun candidat au partitionnement n'apporte de gain d'information supérieur à la valeur de Min Info Gain.
- Aucun candidat au partitionnement ne produit de nœuds descendants, ayant chacun au moins un nombre de lignes égal à Min Instance Per Node.
L'algorithme Random forest exécuté plusieurs fois l'algorithme des arbres de décisions (contrôlé par le paramètre numTrees), sur un sous-ensemble du jeu de données et un sous-ensemble des attributs.
Ces deux sous-ensembles sont gérés par deux paramètres :
- Le taux de sous-échantillonnage : ce paramètre définit la fraction du jeu de données d'entrée utilisé pour apprendre chaque arbre de décision dans une forêt. Le jeu de données est créé selon la méthode de l'échantillonnage par remplacement, ce qui veut dire que, par exemple, une ligne peut être présente plusieurs fois.
- La stratégie d’échantillonnage : ce paramètre définit le nombre d'attributs à prendre en considération pour chaque arbre. Vous pouvez définir l'une des valeurs suivantes :
- auto: la stratégie est automatiquement basée sur le nombre d'arbres dans la forêt.
- all : le nombre total de caractéristiques est considéré pour la division.
- sqrt : le nombre de caractéristiques à considérer est la racine carrée du nombre total de caractéristiques.
- log2: le nombre d'attributs pris en considération est égale à log2(M), où M est le nombre total d'attributs.
Différents arbres seront générées. De nouvelles valeurs peuvent être prédites par vote consensuel au sein de l'ensemble d'arbres.