
Envoyer des données à un topic Kafka
Ce scénario a pour objectif de vous aider à configurer et à utiliser des connecteurs dans un pipeline. Ce scénario doit être adapté en fonction de votre environnement et de votre cas d'utilisation.

Avant de commencer
- Si vous souhaitez reproduire ce scénario, téléchargez et extrayez le fichier test-file-to-kafka.zip .
Procédure
-
Dans le panneau Add a new dataset, nommez votre jeu de données. Dans cet exemple, le topic collette_movies_json sera utilisé pour publier des données relatives à des films.
Exemple

-
Cliquez sur
 et ajoutez un processeur Split (Scission) au pipeline, afin de scinder les enregistrements contenant les prénoms et noms des acteurs et actrices. Le panneau de configuration s'ouvre.
et ajoutez un processeur Split (Scission) au pipeline, afin de scinder les enregistrements contenant les prénoms et noms des acteurs et actrices. Le panneau de configuration s'ouvre.
-
(Facultatif) Consultez l'aperçu du processeur pour voir les données après l'opération de scission.

-
Cliquez sur et ajoutez un processeur Filter (Filtre) au pipeline. Le panneau de configuration s'ouvre.
-
(Facultatif) Consultez l'aperçu du processeur Filter pour voir l'échantillon de données après l'opération de filtre.
Exemple
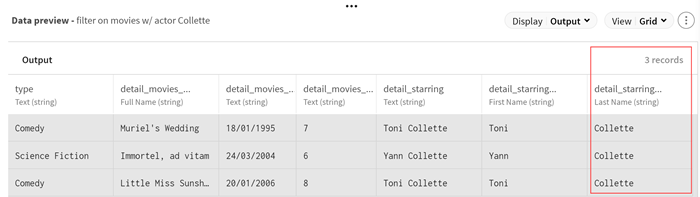
Résultats
Votre pipeline est en cours d'exécution. Les données relatives aux films, provenant de votre fichier test ont été traitées et le flux de sortie est envoyé au topic collette_movies_json défini.
Que faire ensuite
Une fois les données publiées, vous pouvez consommer le contenu du topic dans un autre pipeline et l'utiliser comme source :
