
Talend Data Preparation architecture
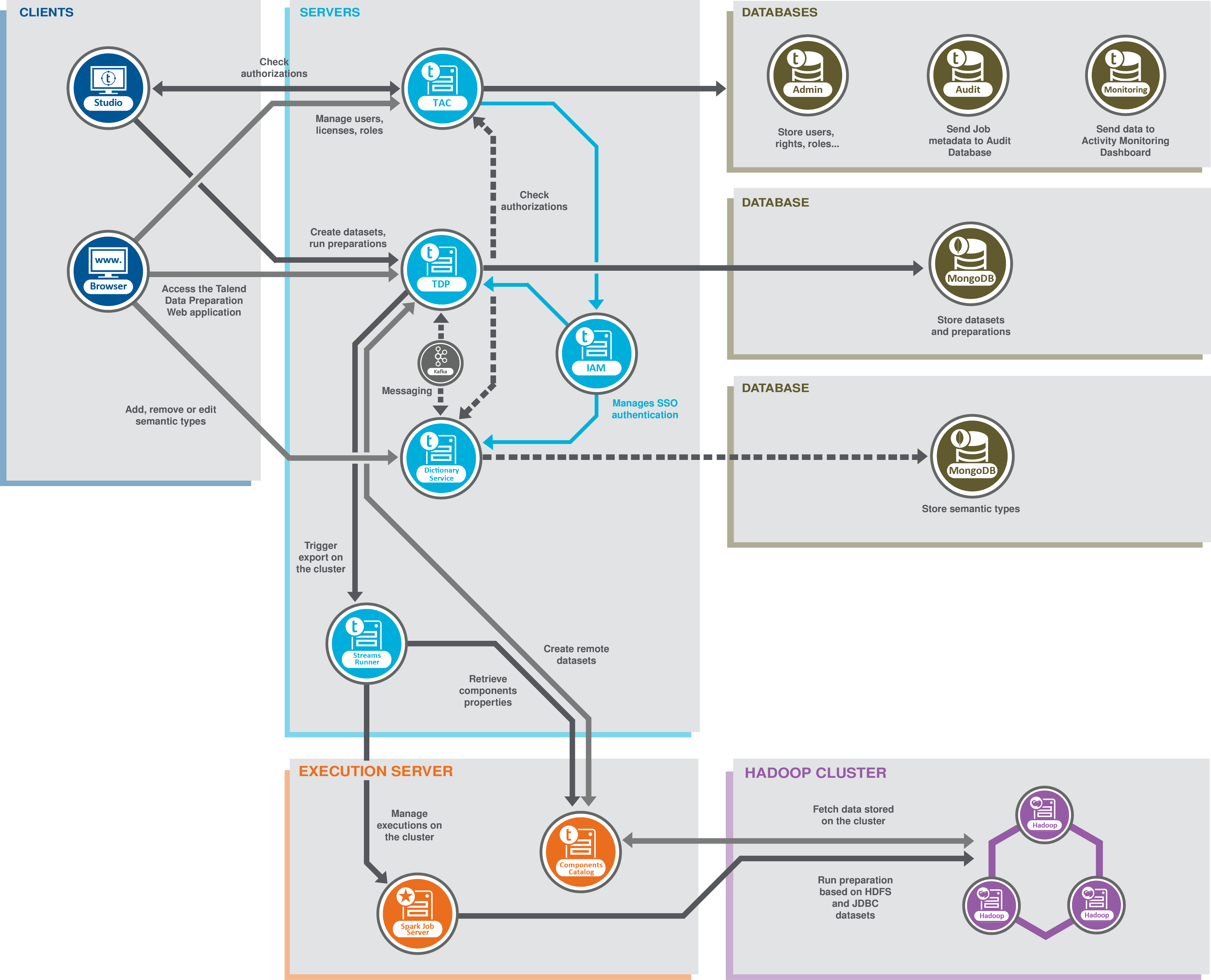
Five different functional blocks are defined:
-
The Clients block, with a Web browser and a Talend Studio.
From the Web browser, you access the Talend Data Preparation Web application. This is where you import your data, from local files or other sources, and cleanse or enrich it by creating new preparations on this data. In addition, you can optionally access Talend Dictionary Service server to add, remove or edit the semantic types used on data in the Web application. For further information, see Enriching the semantic types libraries.
In Talend Studio, you can benefit from the Talend Data Preparation features through the use of the tDatasetInput, tDatasetOutput, and tDataprepRun components. You can create datasets from various databases and export them in Talend Data Preparation, or leverage a preparation directly in a data integration Job or Spark Job.
-
The Servers block includes the Talend Data Preparation application server, connected to Talend Administration Center, and optionally Talend Dictionary Service server and the Streams Runner server. This block also includes a Kafka server used for internal messaging between Talend Data Preparation and Talend Dictionary Service. The Talend Identity and Access Management Service is used to enable Single Sign-On.
Talend Administration Center allows administrators to manage licenses, users and roles. Assigning one or more of the predefined roles to users grants them specific rights to what can they access or perform in Talend Data Preparation. From there, it is also possible to execute Jobs designed in Talend Studio and retrieve a dataset directly in Talend Data Preparation through the use of the Live dataset feature.
In a Big Data context, the Streams Runner service is optionally used to trigger access to the Spark Job Server, whose role is to manage the execution on the Hadoop Cluster, in order to import datasets from the cluster, and run preparation directly on this framework using Beam.
You can optionally use Talend Dictionary Service to add, remove or modify the semantic categories that are applied to each column in your data when opened in Talend Data Preparation.
- The Databases block contains the databases used with Talend Administration Center and a MongoDB database.
The Administration database is used to manage user accounts and rights. The Audit database is used to evaluate different aspects of the Jobs implemented in Talend Studio and the Monitoring database is used to monitor the execution of technical processes and service calls.
The MongoDB database is used to store all your datasets and preparations, as well as the semantic types used to validate your data in the application. Nothing is saved directly on your computer. -
The Execution server block contains a Spark Job Server used to manage the exports that will be performed on the Hadoop cluster, and the Components Catalog.
Thanks to the Components Catalog service, you can import data stored on various types of databases and create remote datasets directly in Talend Data Preparation.
- The Hadoop cluster block, where preparations made on data imported from HDFS or JDBC can be processed when using Talend Data Preparation in a Big Data context.