跳到主要内容
跳到补充内容
Qlik.com
Community
Learning
Qlik 资源
中文(中国) (更改)
Deutsch
English
Français
日本語
中文(中国)
关闭
文档
云
客户端托管
其他文档
云
Qlik Cloud
主页
简介
Qlik Cloud 新增内容
什么是 Qlik Talend Cloud
分析
数据集成
管理
自动化
Qlik 开发人员
Talend Cloud
主页
发行说明
API Portal
其他云解决方案
Stitch
Upsolver
客户端托管
客户端托管 - 分析
面向用户的 Qlik Sense
针对管理员的
Qlik Sense
针对开发人员的
Qlik Sense
Qlik NPrinting
Connectors
Qlik GeoAnalytics
Qlik Alerting
面向用户和管理员的
QlikView
针对开发人员的
QlikView
Governance Dashboard
客户端托管 - 数据集成
Qlik Replicate
Qlik Compose
Qlik Enterprise Manager
Qlik Gold Client
Qlik Catalog
NodeGraph (legacy)
Qlik Talend
Talend Studio
Talend ESB
Talend Administration Center
Talend Data Catalog
Talend Data Preparation
Talend Data Stewardship
其他文档
其他文档
Qlik 文档存档
Talend 文档存档
引导
开始使用分析
开始数据集成
引入分析用户
在
Qlik Sense
中开始使用分析
Administer Qlik Cloud Analytics 标准版
Administer Qlik Cloud Analytics 高级版和企业版
管理
Qlik Sense
Business
管理
Qlik Sense
Enterprise
Saas
Qlik Cloud 政府用户管理员
管理
Windows
版
Qlik Sense
Enterprise
板载数据集成用户
Qlik Talend Data Integration 入门
开始使用 Talend Cloud
视频
迁移中心
评估指南
操作手册
管理员操作手册
Qlik Sense 管理员操作手册
Qlik 资源
中文(中国) (更改)
Deutsch
English
Français
日本語
中文(中国)
搜索
正在加载 SearchUnify 的搜索
如果您需要有关产品的帮助,请联系 Qlik Support。
Qlik 客户门户网站
菜单
关闭
正在加载 SearchUnify 的搜索
如果您需要有关产品的帮助,请联系 Qlik Support。
Qlik 客户门户网站
在此处留下您的反馈
Talend Data Fabric 入门指南
Talend Data Fabric 应用实例
为 Big Data 执行数据集成任务
Spark Streaming 作业入门
场景:将 Avro 数据流写入 HDFS
生成示例数据
在该页面上
步骤
步骤
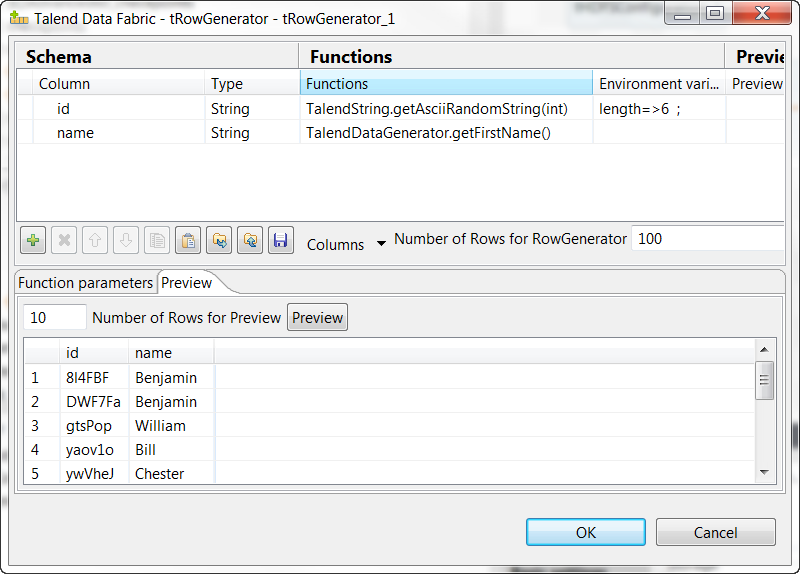
双击
tRowGenerator
以打开其
RowGenerator Editor (RowGenerator 编辑器)
视图。
单击
[+]
按钮两次添加两列,并将其分别命名为
id
和
name (名称)
。
在
Functions (函数)
列中,为
id
选择
TalendString.getAsciiRandomString(int)
函数,为
name (名称)
选择
TalendDataGenerator.getFirstName()
。
在
Number of rows for RowGenerator (RowGenerator 的行数)
字段中,输入每次生成中要创建的行数。在本示例中,输入
100
。
在弹出对话框单击
OK (确定)
以确认这些更改并接受此Schema向后续组件的传播。
在
Basic settings (基本设置)
视图的
Input repetition interval (输入重复间隔)
字段中,输入每次
tRowGenerator
生成一组数据 (
100
行) 结束后间隔的时间 (以毫秒为单位)。在本示例中,是
3000
毫秒。
本页面有帮助吗?
如果您发现此页面或其内容有任何问题 – 打字错误、遗漏步骤或技术错误 – 请告诉我们!
在此处留下您的反馈
上一个主题
配置到 Spark 使用的文件系统的连接
下一个主题
将数据写入 HDFS