
Qlik Catalog Source Properties
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
authorization.hdfs.policy.id
|
HDFS policy ID |
ID populated from security engine |
default=" " |
|
X |
|
|
authorization.hive.policy.id |
Hive policy ID |
ID populated from security engine |
default=" " |
|
X |
|
|
authorization.policy.sync.status |
Indicates Security Policy sync status |
system generated ENUM VALUES: |
default="NEVER_SYNCED" |
|
X |
|
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
cobol.allow.invalid.numeric.as.null |
Facilitates processing of COBOL data which has non-conforming values. When set to TRUE, invalid numeric values will silently map to NULL instead of flagging a BAD/UGLY record. This is especially useful when working with COBOL record layouts that contain REDEFINES clauses Supported at entity and source levels; can be set at the entity level or inherited from the source level. |
TRUE/FALSE |
default="" |
|
X |
|
|
cobol.allow.overflow.redefines |
set to TRUE to allow REDEFINES branches which are larger than the original storage allocation |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.allow.mismatched.record.byte.length |
set to TRUE to allow records shorter than specified copybook layout for VB (Variable Blocked) records |
TRUE/FALSE |
default="" boolean not required |
X |
X |
|
|
cobol.allow.underflow.redefines |
whether or not you want to allow REDEFINES branches which are smaller than the original storage allocation |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.branch.wiring.instructions |
text field containing branch wiring instructions
|
user specified |
default="" |
X |
X |
|
|
cobol.copybook |
the text of the copybook |
automatically populates from COBOL copybook. Not editable. |
default="" |
X |
X |
|
|
cobol.little.endian |
set to TRUE if the source COBOL machine architecture is little endiannon IBM mainframe |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.numproc.nopfd.enabled |
COBOL compiler/environment option NUMPROC(NOPFD) relating to valid/invalid sign nybbles in both ZONED (USAGE DISPLAY) and PACKED (COMP-3) numeric items. |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.record.filter.string |
text field which contains a filter string expression for selecting record types in a COBOL heterogeneous dataset. |
user specified |
default="" |
X |
X |
|
|
cobol.record.layout.identifier |
text field specifies the record type (at 01 Level) extracted for this source |
system defined from COBOL copybook |
default="" |
X |
X |
|
|
cobol.supports.single.byte.binary |
whether or not COBOL compiler supports single byte BINARY/COMP-1 numeric items ... non IBM mainframe |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.sync.alignment.enabled |
COBOL compiler/environment option for SYNC word alignment |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.trunc.bin.enabled |
COBOL compiler/environment option TRUNC(BIN) for truncation of BINARY/COMP-1 numeric items |
TRUE/FALSE |
default="" |
X |
X |
|
|
cobol.unsigned.packed.decimal.uses.sign.nybble |
whether or not the sign nybble holds a digit for unsigned PACKED/COMP-3 |
TRUE/FALSE |
default="" |
X |
X |
|
|
column.pad.short.records |
flag to allow delimited text files with fewer-than-expected number of columns to pass. Extra columns are given NULL field values. |
TRUE/FALSE |
default=FALSE boolean not required |
X |
X |
|
|
conn.jdbc.source.type |
source connection property that holds a reference to database type such as POSTGRES, ORACLE, TERADATA, etc. |
database type string |
default= string required for source connection |
X |
|
|
|
conn.sqoop.mappers.count |
number of mappers to be used to ingest data via sqoop |
number of mappers |
default=4 integer required for sqoop connection, defaults to 4 |
|
X |
|
|
conn.sqoop.schema.name |
name of the database that has within it the table that is used to ingest data via sqoop |
database name string |
default ="" string required for connection |
|
X |
|
|
conn.sqoop.table.name |
name of the table that is used to ingest data via Sqoop string |
table name string |
default="" string required for sqoop ingest |
|
X |
|
|
conn.user.name |
source connection username |
user name string |
default=null string not required |
X |
|
|
|
conn.user.password |
source connection password |
password string |
default=null string not required |
X |
|
|
|
connection.string |
source connection uri that points to the connection location |
connection string |
default="" string required |
X
|
|
|
|
dataset.date.time.extraction.argument |
argument to the extraction method |
value for this property will be either the 'Field Name' (when extraction method value is COBOL_HEADER_FIELD, COBOL_TRAILER_FIELD) |
default="" |
X |
X |
|
|
dataset.date.time.extraction.method |
datetime extraction method |
ENUM VALUES: |
default="" |
X |
X |
|
|
dataset.date.time.pattern |
When datetime extraction method is active, this property defines what format the datetime takes so that it can be accurately found/processed. |
This value defines the format the datetime takes so that it can be parsed correctly when datetime extraction method is active. Patterns are defined using Java SimpleDateFormat pattern specification. |
default="" |
X
|
X |
|
|
dataset.expected.record.count.adjustment |
record offset number adjusts record count |
0 or no entry = record count in the dataset exactly specifies the number of data records. |
default="0" |
X |
X |
|
|
dataset.expected.record.count.excludes.chaff |
allows exclusion of chaff/filtered record count during reconciliation |
TRUE/FALSE TRUE: chaffRecordCount is not included in record count reconciliation FALSE: chaffRecordCount is included in record count reconciliation, (" " empty value is interpreted as false) Any value other than true will be interpreted as false. |
default=”false" boolean not required |
X |
X |
|
|
dataset.expected.record.count.extraction.argument |
each extraction method will have its own way to interpret the argument |
Value for this property will be either the 'Field Name' (when extraction method value is COBOL_HEADER_FIELD |
Default="" |
X |
X |
|
|
dataset.expected.record.count.extraction.method |
record count extraction method |
ENUM VALUES: HEADER_DELIMITED_COLUMN_INDEX TRAILER_DELIMITED_COLUMN_INDEX MANIFEST_DELIMITED_COLUMN_INDEX XML_ELEMENT |
default="" |
X |
X |
|
|
dataset.manifest.file.glob |
location of Manifest File Glob when Record Count Extraction Method is MANIFEST_REGEX or MANIFEST_ENTIRELY |
user specified |
default="" |
X |
X |
|
|
default.date.format |
date format string in Java/JODA date format or vendor-specific date format |
user specified |
default=”” string not required |
X |
X |
|
|
default.field.allow.control.chars |
Boolean controlling whether or not ASCII/Latin-1/Unicode control codes 0x00-0x1F + 0x7F + 0x80-0x9F are allowed in fields |
TRUE/FALSE |
Default="false" |
X |
X |
|
|
default.field.allow.non.ascii.chars |
Boolean controlling whether or not non 7-bit ASCII chars are allowed in fields. Set this at the entity or source level if you expect your content to contain international characters or extended punctuation characters. By default, The application only allows 7-bit US-ASCII characters … US English only. This is the case even if your specified CharEncoding supports other characters. Examples are EBCDIC_037, LATIN_1, and WINDOWS_1252 which support accented Latin characters. All Unicode encodings (UTF_8, UTF_16LE, UTF_16BE, UF_32LE, UTF_32BE) support all major modern languages. |
TRUE/FALSE |
default="" |
X |
X |
|
|
default.field.allow.whitespace |
Boolean controlling whether or not embedded whitespace is allowed in fields. Can be set to false on a string field if you want to ensure that your data contains no embedded spaces. |
TRUE/FALSE |
default="true" |
X |
X |
|
|
default.field.allow.denormalized.whitespace |
optional property detects redundant space characters, but it can also detect presence of NUL bytes in a dataset. |
TRUE/FALSE |
Default="true" |
X |
X |
|
|
default.field.do.not.escape.harmless.control.chars |
flag to indicate that control characters other than \t \r \n should not be backslash escaped. |
TRUE/FALSE |
default="" string not required |
X |
X |
|
|
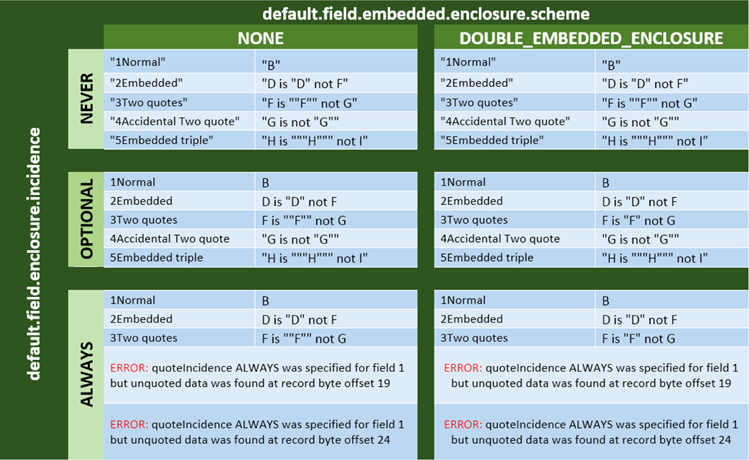
default.field.embedded.enclosure.scheme |
Describes how enclosed/quoted content within a field is to be handled. Go to Behavior of properties field.embedded.enclosure.scheme against field.enclosure.incidence for more information on settings for this property in conjunction with settings for enclosure incidence. |
ENUM VALUES: |
default="" |
X |
X |
|
|
default.field.enclosure.incidence |
incidence of enclosed fields Go to Behavior of properties field.embedded.enclosure.scheme against field.enclosure.incidence for more information on settings for this property in conjunction with enclosure scheme. |
ENUM VALUES: |
default="" |
X |
X |
|
|
default.field.max.legal.char.length |
maximum number of chars allowed in a field |
user specified |
default="250" |
X |
X |
|
|
default.field.min.legal.char.length |
minimum number of chars allowed in a field |
user specified |
default="0" |
X |
X |
|
|
default.field.null.replacement.boolean |
While ingesting data, this entity-level property will replace a null with an alternate value. Alternately this action can be done through Prepare. |
user specified |
default="" |
X |
X |
|
|
default.field.normalize.whitespace |
flag to indicate that string field should be normalized; where leading and trailing whitespace is trimmed and any embedded sequences of embedded whitespace is converted to a single space character. |
TRUE/FALSE |
Default="false" |
X |
X |
|
|
default.field.nullif.pattern |
char sequence which represents the NULL value … exact match or regular expression |
user specified |
default="" |
X |
X |
|
|
default.field.nullif.pattern.is.regex |
Boolean flag which controls whether or not nullif pattern is a regular expression |
TRUE/FALSE |
default="" |
X |
X |
|
|
default.field.trim.left |
Boolean controlling whether or not whitespace should be trimmed from left of fields. Default value is set to "true" at object level unless set "false" in core_env (default.trim=false) |
TRUE/FALSE |
default="true" |
X |
X |
|
|
default.field.trim.right |
Boolean controlling whether or not whitespace should be trimmed from right of fields. Default value is set to "true" at object level unless set "false" in core_env (default.trim=false) |
TRUE/FALSE |
default="true" |
X |
X |
|
|
dock.hand.always.copy.to.loading.dock |
indicates whether entity should always be copied to loading dock for preprocessing (If data is in S3, for example, data will not copy to loading dock by default) |
TRUE/FALSE |
default="false" |
X
|
X |
|
|
enable.archiving |
whether or not inbound files are archived; recommendation is to set this property at parent source level |
TRUE/FALSE |
default="false" |
X |
|
|
|
enable.distribution |
If set to false in core_env.properties, distribution tables will not be created for any entity. |
TRUE/FALSE |
default="true" |
X |
X |
|
|
enable.profiling |
boolean controlling whether or not profiling should be performed on this source/entity/field Note that if profiling is enabled without enabling validation, the risk of corrupt or inaccurate profile values is increased. |
TRUE/FALSE |
default="true" |
X |
X |
X |
| enable.relationInference |
boolean enables/disables relationship inference of all entities. This property is available at source or entity level and can override the default core_env.property and enable (or disable) the catalog from identifying potentially related entities amongst others within the catalog.
|
TRUE/FALSE | default="false" boolean not required |
X | X | |
|
enable.validation |
boolean controlling whether or not field validation should be performed. Dangerous—this value should not be switched to “false” |
TRUE/FALSE |
default="true" |
X |
X |
X |
|
entity.base.type |
indicates whether the data loads into the entity via Snapshot (the default value) where every data set loaded is a full "refresh" of all data for that entity or Incremental where after the first load all subsequent data sets loaded are additions on top of already loaded data. |
ENUM VALUES: |
default="snapshot" |
|
X |
|
|
entity.custom.script.args |
path to the script plus any arguments such as passwords/username and parameters are passed. This property can be set after the object is created via the wizard – as a CUSTOMSCRIPT. If the object is created via JDBC for example, this property will not be there until it is manually entered. |
user defined |
default="" |
|
X |
|
|
entity.fdl |
field format information is parsed from FDL and populated in this property. The text is informational only. |
system-parsed FDL text. Not editable. |
default="" |
|
X
|
|
|
entity.override.local.mode |
allows optional "switch" of ingest from LOCAL or MapReduce. This property can be set for small dataloads to over-ride hadoop.conf.files setting in core_env.properties; allowing for faster local ingest. Entity-level only. |
TRUE/FALSE |
default="" |
|
X |
|
|
entity.postprocessing.rules |
Drools rules engine executes rules after the distribution metadata is created during ingest or dataflow execution. |
user-defined rules ex. entity.postprocessing.rules=List (samples contains "CATALOG") |
Default="" string not required |
X |
X |
X |
|
field.allow.control.chars |
Boolean controlling whether or not ASCII/Latin-1/Unicode control codes 0x00-0x1F + 0x7F + 0x80-0x9F are allowed in this specific field |
TRUE: control characters (including NUL bytes) will be allowed. |
default="false" boolean |
|
|
X |
|
field.allow.denormalized.whitespace |
optional property detects redundant space characters, but it can also detect presence of NUL bytes in a dataset. |
TRUE/FALSE |
default="true" |
|
|
X |
|
field.allow.non.ascii.chars |
Boolean controlling whether or not non 7-bit ASCII chars are allowed in fields. Set this at the entity or source level if you expect your content to contain international characters or extended punctuation characters. By default, the application only allows 7-bit US-ASCII characters … US English only. This is the case even if your specified CharEncoding supports other characters. Examples are EBCDIC_037, LATIN_1, and WINDOWS_1252 which support accented Latin characters. All Unicode encodings (UTF_8, UTF_16LE, UTF_16BE, UF_32LE, UTF_32BE) support all major modern languages. |
TRUE/FALSE |
default="" |
|
|
X |
|
field.allow.whitespace |
Boolean controlling whether or not embedded whitespace is allowed in fields. Can be set to false on a string field if you want to ensure that your data contains no embedded spaces. |
TRUE/FALSE |
default="true" |
|
|
X |
|
field.date.format |
date format string in Java/JODA date format or vendor-specific date format for this specific field |
user specified |
default="" |
|
|
X |
|
field.do.not.escape.harmless.control.chars |
boolean controlling whether to ignore harmless 7-bit ASCII/Latin-1/Unicode control chars. This flag indicates that control characters other than \t, \r, and \n should not be backslash escaped. |
TRUE/FALSE |
default="false" |
|
|
X |
|
field.embedded.enclosure.scheme |
Describes how enclosed/quoted content within a field is to be handled. Go to Behavior of properties field.embedded.enclosure.scheme against field.enclosure.incidence for more information on settings for this property in conjunction with settings for enclosure incidence |
ENUM VALUES: |
default="" |
|
X |
|
|
field.enclosure.incidence |
incidence of enclosed fields Go to Behavior of properties field.embedded.enclosure.scheme against field.enclosure.incidence for more information on settings for this property in conjunction with enclosure scheme |
ENUM VALUES: OPTIONAL |
default="" |
|
|
X |
|
field.fdl |
field format information is parsed from FDL and populated in this property. The text is informational only. |
system-parsed FDL text, not editable |
default="" |
|
X |
|
|
field.info.file |
FDL property: pointer to field info file (optional as information may exist in current file). |
system-parsed FDL text, not editable |
default="" |
|
|
X |
|
field.hive.ddl.data.type |
field-level property using DDL (Data Definition Language) which allows one to define a data type for the respective field which will be used when the hive/hcatalog is created. |
auto-populated upon ingest or user-defined
|
DECIMAL default=DECIMAL($precision,$scale)
STRING Default=VARCHAR($length) (where $length is actually $precision) |
|
|
X |
|
field.max.legal.char.length |
maximum number of chars allowed in this specific field |
auto-populated upon ingest |
default=($length) (where $length is actually $precision) |
|
|
X |
|
field.max.legal.value |
maximum legal value for this specific field … interpretation depends upon field type |
user specified |
default="" |
|
|
X |
|
field.min.legal.char.length |
minimum number of chars allowed in this specific field |
user specified |
default="0" |
|
|
X |
|
field.min.legal.value |
minimum legal value for this specific field … interpretation depends upon field type |
user specified |
default="" |
|
|
X |
|
field.normalize.whitespace |
applies string normalization: leading and trailing whitespace is trimmed and any embedded sequences of embedded whitespace is converted to a single space character. |
TRUE/FALSE |
Default="" |
|
|
X |
|
field.null.replacement |
replaces NULL values with an alternate value |
user specified |
default="" |
|
|
X |
|
field.nullif.pattern |
char sequence which represents the NULL value –exact match or regular expression |
user specified |
default="" |
|
|
X |
|
field.nullif.pattern.is.regex |
boolean flag which controls whether or not nullif pattern is a regular expression |
TRUE/FALSE |
default=false |
|
|
X |
|
field.number.format |
the number format to parse input value into a DOUBLE/DECIMAL/INTEGER field. For details see https://docs.oracle.com/javase/7/docs/api/java/text/DecimalFormat.html note: field.number.format can specify sub-patterns for negative and positive numbers using java.text.DecimalFormat notation. e.g. field.number.format=¤#,##0.00;(¤#,##0.00) and field.number.currencySymbol=$ will parse the numbers like (¤ is the placeholder for currency symbol). $1000000.54=1000000.54 ($1000000.54)=-1000000.54 |
Automatically set for QVDs based on information in the QVD header. For non-QVD entities these properties are null (not set) by default and have to be set by the user manually. |
default="" string not required |
|
|
|
|
field.number.decimalSeparator |
the decimal separator to use for number parsing (single-character) note: A comma "," is supported as a decimal separator but in that case, the thousand separator must be different (ex.,period ".") and must be specified even if the field does not contain numbers in the thousands. Similarly, if the thousand separator is period (.) then decimal separator must be different (ex., comma) and must be specified even if field does not contain decimals (if it is an INTEGER and the decimal point will not display). |
Automatically set for QVDs based on information in the QVD header. For non-QVD entities these properties are null (not set) by default and have to be set by the user manually. |
default="." (period) string not required |
|
|
|
|
field.number.thousandSeparator |
the thousandths separator to use for number parsing (single-character) note: A comma "," is supported as a decimal separator but in that case, the thousand separator must be different (ex.,period ".") and must be specified even if the field does not contain numbers in the thousands. Similarly, if the thousand separator is period (.) then decimal separator must be different (ex., comma) and must be specified even if field does not contain decimals (if it is an INTEGER and the decimal point will not display). |
Automatically set for QVDs based on information in the QVD header. For non-QVD entities these properties are null (not set) by default and have to be set by the user manually. |
default="" string not required |
|
|
|
|
field.number.currencySymbol |
the currency symbol for number parsing. Note that if this property is set on a field, the field must contain currency symbols like $1000 |
user specified |
default="" string not required |
|
|
|
|
field.number.minusSymbol |
the negative symbol for numbers (single-character) |
user specified |
default="-"(dash) string not required |
|
|
|
|
field.obfuscation.rule |
used at field level to mask the data. The property points to a data masking algorithm fetched from the database upon specification of field as "sensitive". |
user specified |
default=<obfuscationrule> string required for sensitive fields |
|
|
X |
|
field.sensitive |
boolean indicates if field is sensitive |
TRUE/FALSE |
default=false |
|
|
X |
|
field.trim.left |
boolean controlling whether or not whitespace should be trimmed from the left of this specific field. Default value is set to "true" at object level unless set "false" in core_env (default.trim=false) |
TRUE/FALSE |
default=true |
|
|
X |
|
field.trim.right |
boolean controlling whether or not whitespace should be trimmed from the right of this specific field. Default value is set to "true" at object level unless set "false" in core_env (default.trim= false) |
TRUE/FALSE |
default=true |
|
|
X |
|
hadoop.conf.mapreduce.job |
assigns a job to particular queue |
user specified |
Default="" string not required |
|
X |
|
|
header.byte.count |
specifies a fixed header byte count at the entity level |
user modifiable |
default="0" |
|
X |
|
|
header.charencoding |
specifies character encoding for the header |
system generated |
default= |
|
X |
|
|
header.defines.field.names |
boolean which indicates whether or not the header specifies the field names |
TRUE/FALSE |
default=false boolean not required |
|
X |
|
|
header.line.count |
specifies header line count for text files (entity-level) |
user modifiable |
default=" " |
|
X |
|
|
header.record.count |
accounts for the RDW on header record for MAINFRAME_VARIABLE_RDW_ONLY |
" " (null) or 0= no RDW 1= RDW |
default=" " integer not required |
|
X |
|
|
header.validation.pattern |
pattern for validating header, either exact string match or regular expression |
user specified |
default="" |
|
X
|
|
|
header.validation.pattern.is.regex |
Boolean flag which controls whether or not header validation pattern is a regular expression |
TRUE/FALSE |
default=”false” |
|
X |
|
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
kafka.max.total.records |
Maximum number of records to consume from Kafka in one load. Once the entity is created, entity-level Kafka properties can be set. |
user modifiable |
default=”1000” integer required |
|
X |
|
|
kafka.poll.timeout.ms |
Timeout for one poll of the Kafka queue. This each poll tries to consume up to 100 records. Several polls may be made per load. Once the entity is created, entity-level Kafka properties can be set. |
user modifiable |
default=”10000” integer required |
|
X |
|
|
kafka.record.buffer.size |
Size, in records, of the buffer while pulling data from Kafka. Once the entity is created, entity-level Kafka properties can be set. |
user modifiable |
default=”1000” integer required |
|
X |
|
|
kafka.start.offset |
Starting position for the next Kafka load. Once the entity is created, entity-level Kafka properties can be set. |
user modifiable, Can be one of: END, BEGINNING, <long integer value>. |
default=END string required |
|
X |
|
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
hive.exec.orc.default.block.padding |
Padding ensures that stripes don't straddle HDFS blocks. |
user modifiable={TRUE/FALSE} |
hadoop default="true" |
hadoop prop | ||
|
hive.exec.orc.write.format |
Define the version of the file to write. Possible values are 0.11 and 0.12. |
user modifiable={0.11 and 0.12} |
hadoop default=".12" |
hadoop prop | ||
|
hive.exec.orc.default.compress |
High level compression |
user modifiable={NONE, ZLIB, SNAPPY} |
hadoop default="ZLIB" |
hadoop prop | ||
|
hive.exec.orc.default.buffer.size |
Define the default ORC buffer size, in bytes |
user modifiable |
hadoop default="262,144" |
hadoop prop | ||
|
hive.exec.orc.default.row.index.stride |
Number of rows between index entries |
user modifiable |
hadoop default="10,000" |
hadoop prop | ||
|
hive.exec.orc.default.stripe.size |
Memory buffer size in bytes for writing |
user modifiable |
hadoop default="268,435,456" |
hadoop prop | ||
|
hive.object.location |
Optional entity-level property that controls Hive table location (a user specified HDFS location). The value for this property has to be in place for the first load. Changing it will not change the location once it has been set. If this property changes, the entity should be recreated. |
User specified |
default="" |
|
X
|
|
|
mapred.job.arguments |
passes job configurations with arguments to mappers and reducers |
user specified |
default="" |
X |
X |
|
|
numeric.precision.scale.rounding.mode |
An entity field can specify a numeric fixed point precision and scale. Used for validation and to conform incoming data to a desired format. Currently, this property can be applied to data fields declared to be of type DOUBLE. |
user specified |
DECIMAL: |
|
|
X |
|
original.name |
Holds original entity name. Entity names with special characters or spaces are sometimes changed to SQL-compatible names. |
user specified |
default="" |
|
X |
|
|
originalSourceName |
name of original external data source |
user modifiable |
default="" |
X |
|
|
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
parquet.block.size |
Size of a row group being buffered in memory. |
user modifiable |
hadoop default="134,217,728" |
hadoop prop | ||
|
parquet.enable.summary.metadata |
Summary metadata files produced at the end of MR jobs |
user modifiable |
hadoop default="1" |
hadoop prop | ||
|
parquet.memory.pool.ratio |
Ratio of the heap the parquet writers should use |
user modifiable |
hadoop default="0.95" |
hadoop prop | ||
|
parquet.memory.min.chunk.size |
Limit to how small the Parquet writer will make row groups. If a row group is smaller than this, it will kill the job. |
user modifiable |
hadoop default="1 MB" |
hadoop prop | ||
|
parquet.compression |
Compression codec to use. Supersedes mapred.output.compress. |
user modifiable={UNCOMPRESSED, GZIP, SNAPPY, LZO} |
hadoop default="UNCOMPRESSED" |
hadoop property, and can also be set at Entity for Ingest. To define for Prepare Targets, use global parameter "parquet.compression" and set with same method options. Note the global parameter is applied to all targets for one workflow. | ||
| podium.qlik.dataconnection.name |
Name of connection to source database in Qlik Sense. *This property must be manually defined on internal objects in discover! |
user specified. This property can be used to assist in two distinct scenarios. One use case is to facilitate per user connection security in single node implementaions. See Qlik Sense Connection Name in User Profile and Preferences. The other use case is to assist in generation of a loadscript for dataload to Qlik Sense in cases where registered and addressed entities are published to Qlik Sense without data loaded. For more information, see Publish to Qlik properties.
|
default="" string not required |
X | X | |
| podium.qlik.script |
Load statement as applicable to source system. *This property must be manually defined on internal objects in discover! |
user specified. Script should have the following information: LIB CONNECT TO [<QS_CONNECTION_NAME>]. If this script is defined, properties podium.qlik.dataconnection.name and podium.qlik.select.statement do not have to be defined. For more information, see Publish to Qlik properties. | default="" string not required |
X | ||
| podium.qlik.select.statement |
SQL load statement to retrieve specified result set of records. *This property must be manually defined on internal objects in discover! |
user specified. Assists in generation of a loadscript for dataload to Qlik Sense in cases where registered and addressed entities are published to Qlik Sense without data loaded. For more information, see Publish to Qlik properties. | default="" string not required |
X | ||
|
posix.directory.acl |
entity or source levels. specifies access control list permissions to be set for directories during ingestion of entity data. |
user specified (same syntax as required by the command line -setfacl command) |
default="" |
X |
X |
|
|
posix.directory.group.identifier |
entity or source levels. specifies the group identifier that should be set for directories during ingestion of entity data. |
user specified |
default="" |
X |
X |
|
|
posix.directory.permissions |
entity or source levels. specifies permissions mask to be set for directories during ingestion of entity data. |
user specified (9 character string in standard rwxDash format: rw-rw----) |
default="" |
X |
X |
|
|
posix.directory.user.identifier |
entity or source levels. specifies the user identifier that should be set for directories during ingestion of entity data. |
user specified |
default="" |
X |
X |
|
|
posix.file.acl |
entity or source levels. specifies access control list permissions to be set for files during ingestion of entity data. |
user specified (same syntax as required by the command line -setfacl command) |
default="" |
X
|
X |
|
|
posix.file.group.identifier |
entity or source levels. specifies group identifier to be set for files during ingestion of entity data. |
user specified |
default="" |
X |
X |
|
|
posix.file.permissions |
entity or source levels. specifies permissions mask to be set for files during ingestion of entity data. |
user specified (9 character string in standard rwxDash format: rw-rw----) |
default="" |
X |
X |
|
|
posix.file.user.identifier |
entity or source levels. specifies the user identifier that should be set for files during ingestion of entity data. |
user specified |
default="" |
X |
X |
|
|
profile.integer.census.cardinality.limit |
Controls the PROFILE_INTEGER_CENSUS_CARDINALITY_LIMIT. This property can be set at the at the field, entity, source, and core_env levels. |
Discrete INTEGER values are discrete and are often used for "codes" to indicate current status or state. |
default="100" |
X |
X
|
X |
|
profile.string.sample.cardinality.limit |
controls the PROFILE_STRING_SAMPLE_CARDINALITY_LIMIT for both CENSUS and SAMPLE surveys. |
A sample survey is conducted on STRING fields to build a data profile that reflects the data distribution of STRING field values. |
default="4000" |
X |
X |
X |
|
profile.string.sample.char.length.limit |
controls upper limit of sample character length of STRING value fields: PROFILE_STRING_SAMPLE_CHAR_LENGTH_LIMIT. This property can be set at the field, entity, source, or core_env levels, with inheritance. |
A sample survey is conducted on STRING fields to build a data profile that reflects the data distribution of STRING field values. STRING fields which contain discrete values are generally quite short. If a given STRING field contains long strings with a large number of characters then there is usually little/no repetition of values, cardinality is very high, and the data distribution histogram is of little value.
Before version 3.1, PROFILE_STRING_SAMPLE_CHAR_LENGTH_LIMIT was hard-wired to 100. That is, if a STRING field contained a value with more than 100 chars then the SAMPLE SURVEY would be discarded. |
default="100" |
X |
X |
X |
|
qs.connectorInfo.nid |
QS connector info number id |
obtained from QS Connector Info Metadata |
default="" |
QVD Source Conn X |
|
|
|
qs.publish.count |
QS publish count |
count of times an entity has been published to Qlik |
default="" |
X |
|
|
|
qvd.file.entity.createtime |
QVD file datetime |
system-managed: obtained from File Scanner and QVD File modified time |
default="" |
|
QVD X |
|
|
qvd.file.entity.creator |
QVD file creator |
system-managed: obtained from File Scanner and QVD File creator |
default="" |
|
QVD X |
|
|
qvd.file.entity.filesize |
QVD file size |
system-managed: obtained from File Scanner and QVD File size |
default="" |
|
QVD X |
|
|
qvd.file.entity.numupdates |
QVD file number of updates |
system-managed: obtained from File Scanner and QVD File updates |
default="" |
|
QVD X |
|
|
qvd.file.entity.original.name |
QVD file original name |
system-managed: obtained from QVD File name |
default="" |
|
QVD X |
|
|
qvd.file.entity.owner |
QVD file owner |
system-managed: obtained from File Scanner and QVD File owner. Owner means the owner app. |
default="" |
|
QVD X |
|
|
qvd.file.entity.updatetime |
QVD file update time |
system-managed: obtained from File Scanner and QVD File modified time |
default="" |
|
QVD X |
|
|
qvd.file.linux.folder |
QVD file parent directory |
system-managed: obtained from File Scanner |
default="" |
|
QVD X |
|
|
qvd.file.linux.path |
QVD linux path |
system-managed: QS install's linux mount point and QVD folder path. It is used to identify unique folder path to one or more QVD's. |
default="" |
|
QVD X |
|
|
qvd.file.windows.full.path |
QVD file windows full path |
user-defined upon QVD import |
default="" |
|
QVD X |
|
|
qvd.header |
QVD header |
system-managed: XML header backup |
default="" |
|
QVD X |
|
|
qvd.header.entity.Comment |
QVD comment |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.CreateUtcTime |
QVD creation time on Qlik Sense |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.CreatorDoc |
QVD creator application reference |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.NoOfRecords |
QVD number of records |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.QvBuildNo |
QVD build number |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.TableName |
QVD table name |
system-managed: obtained from QVD header for a QVD type entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.entity.tags |
QVD tags |
system-managed in Qlik Catalog, tags are created in Qlik Sense and obtained from QVD header for a QVD entity when it's created |
default="" |
|
QVD X |
|
|
qvd.header.field.Comment |
QVD comment |
system-managed: obtained from QVD header for a QVD type entity - field when it's created. Users might have valuable data about the QVD or Field in comments. |
default="" |
|
|
QVD X |
|
qvd.header.field.Name |
QVD field name |
system-managed: obtained from QVD header for a QVD type entity - field when it's created |
default="" |
|
|
QVD X |
|
qvd.header.field.NoOfSymbols |
QVD number of symbols |
system-managed: obtained from QVD header for a QVD type entity - field when it's created. It is related to the Cardinality. |
default="" |
|
|
QVD X |
|
qvd.header.field.tags |
QVD field tags |
system-managed: obtained from QVD header for a QVD type entity - field when it's created |
default="" |
|
|
QVD X |
|
qvd.qs.connection.names |
QVD connection names |
system-managed: obtained from Qlik Sense instance |
default="" |
QVD Source Conn X |
|
|
|
qvd.qs.data.connection.path |
QVD connection paths |
system-managed: obtained from Qlik Sense instance |
default="" |
QVD Source Conn X |
|
|
|
qvd.qs.install.connection.guids |
QVD Qlik Sense Connection ID |
system-managed: obtained from Qlik Sense instance |
default="" |
QVD Source Conn X |
|
|
|
qvd.qs.install.guid |
QVD Qlik Sense Install Instance ID |
system-managed: obtained from Qlik Sense instance |
default="" |
QVD Source Conn X |
|
|
|
record.characterset |
char encoding of the data records |
ENUM VALUES: |
default="" |
|
X |
|
|
record.close.quote |
default field close enclosure |
user specified* *Any character(s) can be used as the delimiter in data. The delimiter can be coded however the incoming file character set encodes that character. For example, if the delimiter is the broken pipe character: ¦, the delimiter can be encoded for the incoming character set: UTF-8 (hex): 0xC2 0xA6 (c2a6) UTF-16 (hex): 0x00A6 (00a6) Latin-1: \xA6 Unicode: U+00A6 |
default="" |
|
X |
|
|
record.field.delimiter |
character(s) used to separate groups of fields |
user specified*
*Any character(s) can be used as the delimiter in data. The delimiter can be coded however the incoming file character set encodes that character. For example, if the delimiter is the broken pipe character: ¦, the delimiter can be encoded for the incoming character set: UTF-8 (hex): 0xC2 0xA6 (c2a6) UTF-16 (hex): 0x00A6 (00a6) Latin-1: \xA6 Unicode: U+00A6 |
default="" |
|
X |
|
|
record.fixed.byte.count |
a fixed byte count valid when record.layout == "FIXED_BYTE_LENGTH" or "FIXED_BYTE_LENGTH_TERMINATED" |
user specified |
default="-1" |
|
X
|
|
|
record.last.field.has.delimiter |
set to true if the last field in each has a delimiter |
TRUE/FALSE |
default=false |
|
X |
|
|
record.layout |
defines how the record is laid out (fixed, variable, etc.) |
ENUM VALUES: |
default="" |
|
X
|
|
|
record.max.byte.count |
maximum valid record byte length |
user specified |
default="65536" |
|
X |
|
|
record.min.byte.count |
minimum valid record byte length |
user specified |
default="1' |
|
X |
|
|
record.open.quote |
default field open enclosure |
user specified*
*Any character(s) can be used as the delimiter in data. The delimiter can be coded however the incoming file character set encodes that character. For example, if the delimiter is the broken pipe character: ¦, the delimiter can be encoded for the incoming character set: UTF-8 (hex): 0xC2 0xA6 (c2a6) UTF-16 (hex): 0x00A6 (00a6) Latin-1: \xA6 Unicode: U+00A6 |
default="" |
|
X |
|
|
record.record.terminator |
record terminator char sequence for FIXED_LENGTH_TERMINATED and VARIABLE_LENGTH_TERMINATED |
user specified |
default="" |
|
X |
|
|
record.sampling.probability |
option to reset default probability (.01) sampling fraction (1/100) of dataset values for sample directory |
Qlik Catalog creates a sample directory upon creation of entities for inclusion in publish or prepare flows. Sample data probability can be set in core_env.properties (default.record.sampling.probability) or at source or entity level properties (record.sampling.probability) with a default value of .01 (at all levels). Entity level value can over-ride source level value which can over-ride the global value set in core_env.properties. To set the sample probability of the entire original dataset to include all records specify a value of 1.0. To include half of the records, specify a value of .5. To set the sample set to none (no sample records) specify a value of 0. |
default=".01" |
X |
X |
|
|
record.validation.regex |
optional regular expression used to validate a record |
regular expression |
default="" |
|
X |
|
|
resource_uri |
location of source file |
user specified |
default="" |
X |
|
|
|
s3.read.by.data.nodes |
advanced feature used for AWS S3 processing to bypass loading dock |
TRUE/FALSE |
default="false" |
X |
X |
|
|
src.comm.protocol |
inbound communication protocol |
ENUM VALUES: FTP KAFKA OPENCONNECTOR S3 SFTP WASB WASBS |
default="" |
X |
|
|
|
src.connection.file |
location of CONNECTION INFO FILE |
user specified |
default="" |
X |
|
|
|
sourceDataBaseTypeName |
JDBC database type name registered with driver |
system defined |
default="" |
X |
|
|
|
src.entity.name |
business name of entity/table |
user specified |
default="" |
X |
|
|
|
src.file.glob |
wild card glob of data files for this source |
user specified |
default="" |
|
X |
|
|
src.sys.name |
internal business name for data source |
user specified |
default="" |
X |
|
|
|
src.sys.type |
source system type |
ENUM VALUES: |
default="" |
X |
|
|
|
trailer.byte.count |
specifies a fixed header byte count, entity level |
user specified |
default="0" |
|
X |
|
|
trailer.charenconding |
specifies character encoding for the trailer |
ENUM VALUES: |
default="" |
|
X |
|
|
trailer.control.z.at.eof.incidence |
Incidence of an expected CTL-Z at EOF in text files from legacy MS-DOS and Windows |
NEVER, OPTIONAL, ALWAYS |
default="OPTIONAL" |
|
X |
|
|
trailer.line.count |
specifies trailer line count for text files (entity-level) |
user specified |
default="0" |
|
X |
|
|
trailer.record.count |
accounts for the RDW on trailer record for MAINFRAME_VARIABLE_RDW_ONLY |
" " (null) or 0= no RDW 1= RDW |
default=" " integer not required |
|
X |
|
|
trailer.validation.pattern |
pattern for validating trailer ... either exact string match or regular expression |
user specified |
default="" |
|
X |
|
|
trailer.validation.pattern.is.regex |
Boolean flag which controls whether or not trailer validation pattern is a regular expression |
TRUE/FALSE |
default="" |
|
X |
|
|
unicode.byte.order.mark |
type of Unicode Byte Order Mark for Unicode text files. |
ENUM VALUES: UTF_32LE_BOM, UTF_32BE_BOM, UTF_8_BOM, UTF_16LE_BOM, UTF_16BE_BOM |
default=null |
|
X |
|
|
unicode.byte.order.mark.incidence |
expected incidence of Unicode Byte Order Mark |
NEVER, OPTIONAL, ALWAYS |
default=null |
|
X |
|
|
use.single.receiving.mapper |
use single mapper instead of multiple split mappers. (Sometimes useful for debugging or as a workaround) |
TRUE/FALSE |
default="false" |
X |
X |
|
| SOURCE PROPERTY |
DESCRIPTION |
VALUES |
ATTRIBUTES |
SOURCE |
ENT |
FIELD |
|---|---|---|---|---|---|---|
|
xml.entity.namespaces |
list of XML namespaces described by the XSD |
system defined, generated by XSD to Metadata routine |
default="" |
|
X |
|
|
xml.entity.xmlRoot |
name of parent element to all other elements NOT USED |
system defined, generated by XSD to Metadata routine |
default="" |
|
X |
|
|
xml.field.isKey |
indicates whether field was marked as a key in XSD |
system defined, generated by XSD to Metadata routine |
default="" |
|
|
X |
|
xml.field.xsltExpr |
xpath of the field relative to the entity path |
system defined, generated by XSD to Metadata routine |
default="" |
|
|
X |
|
xml.entity.xsd |
contains specifications describing the elements in an XML document |
system defined, text of XSD uploaded via XML wizard/generated by XSD to Metadata routine |
default="" |
|
X |
|
|
xml.entity.xslt |
contains XML style sheet for transforming XML into CSV file |
system defined, generated by XSD to Metadata routine |
default="" |
|
X |
|
|
xml.entity.xpath |
xpath to the XML element corresponding to this entity |
system defined, generated by XSD to Metadata routine |
default="" |
|
X |
|
Behavior of properties field.embedded.enclosure.scheme against field.enclosure.incidence
Original Data File

Field Behavior as Function of Enclosure Scheme and Incidence Settings
Publish to Qlik properties
Three properties (podium.qlik.dataconnection.name, podium.qlik.script, and podium.qlik.select.statement) used together solve the issue where Publish to Qlik does not distinguish between managed or (registered and addressed) entities. When a registered or addressed non-QVD entity is published to Qlik it will publish without data or a native capability to load the data. The property podium.qlik.script can be created from the properties podium.qlik.dataconnection.name and podium.qlik.select.statement to load data into Qlik Sense from its original source. The property podium.qlik.script can be explicitly defined, in which case the other two property values are ignored.
podium.qlik.dataconnection name: Qlik Sense Connection name points to the original source system known to Qlik Catalog (ex., RDBMS, file server, etc.) This property exists at the core_env (global) level and source and entity. If defined at entity level, the entity level value will over-ride source and core_env value. If defined at the source level, it will over-ride core_env value. This connection name must be created or exist in Qlik Sense.
podium.qlik.script: Proper load script with dataconnection name and select statement facilitates data load to Qlik Sense. Neither of the other two properties (podium.qlik.dataconnection.name and podium.qlik.select.statement) have to be defined if this script is defined. If the other properties have values, they will be ignored.
podium.qlik.select.statement: Users specify and populate this statement in which case it becomes the select statement and the application will not attempt to create the select statement. The select statement provided must be syntactically correct as a proper load statement per standards and syntax required for that source system.
Notes:
-
This mechanism is intended for registered and addressed non-QVD entities, though there are use cases where it could be used to over-write load scripts for managed entities and QVDs. If podium.qlik.script is defined this can also be used for managed entities and QVDs and will over-ride the auto-generated loadscript.
-
This is especially useful for single node entities where most objects are registered.
-
While all three properties can be defined, only either both podium.qlik.dataconnection.name and podium.qlik.select.statement OR podium.qlik.script is required.