Publish: add target
Publish target definition configures connection and database credentials for each publish operation.
This process defines Target Type, Target Name, Connection URI and other properties relevant to the target type.
In Publish, select Target to open target tab; then select Add Target.

Target definition window displays with fields specific to the type of target being defined.
For example, Hadoop targets require a Hive URI as Hadoop objects necessitate the creation of a Hive table on top of the HDFS file.
All other file-based target types require a URI: File, HDFS, FTP, S3, ADLS) along with user-defined file specifications.
OpenConnector targets require a Custom Script Command and accompanying arguments.
Publish target types
Qlik Catalog provides the following publish target types:
- Amazon – S3 and Redshift: Object-based massively scalable, cloud-based data warehouse storage
- File on ADLS Storage: File-based targets published to MS cloud solution Azure Data Lake Store
- File on FTP Server: File-based targets published to an FTP server over an enterprise network
- File on Qlik Catalog Server: File-based targets are published to a directory on the local host
- File on S3 Storage: File-based targets published to scalable cloud storage
- File on SFTP Server: File-based targets published to an FTP server over an enterprise network via secure SSH tunnel
- File on WASB Storage: Objects publish to Azure's object storage option (Windows Azure Storage Blob) in containers with data in form of blobs
- File on WASBS Storage: Objects publish to Azure's object storage option (Windows Azure Storage Blob) in containers with data in form of blobs, using SSL certificates for improved security
- Hadoop – HDFS and Hive: Entities are registered to Hive tables on top of HDFS
- HDFS: File-based targets published to Hadoop file system
- Open Connector/ RDBMS: File-based targets published to RDBMS via Sqoop transfer
- Qlik Cloud Services – S3: On-premises QVD data is published to pre-configured AWS S3 buckets accessible to Qlik Cloud
Add Amazon – S3 and Redshift target
Amazon – S3 and Redshift publish target requires an S3 target URI with Access Key and Secret Access Key and Redshift target URI.
File Format specifications are not required.
| Target format spec | Values |
|---|---|
|
Target Name |
user defined |
|
Target Type |
Amazon – S3 and Redshift |
|
S3 Target URI |
examples: s3a://<host.name.com>/ s3a://test.nvsvpn.com/
The desired scheme (e.g., s3a or s3) should be specified in the connection string. Scheme s3 should be used in EMR (where it is maintained by AWS). Scheme s3a should be used otherwise. Scheme s3n is obsolete and should not be used. |
|
Connection Credentials |
Optional, dependent on cluster security configuration examples: Access Key: AKIAILTC3ORF95TGYH45 Secret Access Key: kijf5tslHYJuykPPrVhhd0Tbj8RaHx8H3SffeSv8 |
|
Redshift Target URI |
examples: jdbc:redshift://[Host]:[Port]/[Schema];[Property1]=[Value];[Property2]=[Value] jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev
|
|
Connection Credentials |
Optional, dependent on cluster security configuration. To generate Redshift credentials, see Using IAM Authentication to Generate User Credentials examples: Username: awsuser Password: ABCD1234 Database Role: arn:aws:iam::715941452413 |
Test Connection and Save the Target.

Add File onADLS storage, FTP server, Qlik Catalog server, S3 storage, SFTP server, WASB storage, WASBS storage publish target
These target types are addressed together here because the specifications are very similar. Enter the following values for file-based targets:
| Target format spec | Values | ||||||
|---|---|---|---|---|---|---|---|
|
Target Type |
Options: ADLS Storage, FTP Server, Qlik Catalog Server (formerly LocalFile), S3 Storage, SFTP Server, WASB Storage, WASBS Storage |
||||||
|
Target Name |
User defined |
||||||
|
URI |
examples: ADLS Gen 1: adl://qdcdevlake1.azuredatalakestore.net/ ADLS Gen2:abfs[s]://abfstestfs@<storage_account_name>.dfs.core.windows.net/ See also ADLS Gen2 notes FTP: ftp://192.168.126.23:21 Qlik Catalog Server file:///usr/local/podium/publish S3: s3a://test.nvsvpm.com/ SFTP: sftp://acmecorp.corp.podiumdata.com See also File on SFTP Server notes WASB: wasb://container1@podiumdevblob1.blob.core.windows.net/ WASBS: wasb://container1@podiumdevblob1.blob.core.windows.net/ Target directory path for localfile access is specified by core_env property: localfile.base.dir.publish.target=usr/local/qdc/publish (default)
This property is used to limit access control over directories on publish targets. |
||||||
|
Entity File Format |
Options: TEXTFILE: Flat File containing only printable characters (usually from ASCII char set) PARQUET: Columnar data format where data is stored and grouped in columns resulting in higher and more efficient compression ratios |
||||||
|
Connection Credentials |
optional, dependent on cluster security configuration |
||||||
|
Field Delimiter |
Options*: (default) tab (\t) comma (,) pipe (|) semi-colon (;) colon (:) CTRL+A (\x01) space (\x20) double pipe (||) pipe tilde (|~)
|
||||||
|
Record Delimiter/Terminator |
default: \n (Newline) |
||||||
|
Header (include field names?) |
Yes|No |
||||||
Test Connection and Save the target.
Example: Add Target for File on Qlik Catalog Server

Select the folder icon (circled above) to browse local server directory to configure File URI

File on SFTP Server notes
If it doesn't the connection will fail with invalid key exception.
Example: Add Target for File on SFTP Server

ADLS Gen2 notes
ADLS Gen2 details for a Publish target:
- ADLS URI:
syntax: abfss://<container>@<storage_account_name>.dfs.core.windows.net/
example: abfss://abfstest@exadlsgen2test1.dfs.core.windows.net/ - Username:<storage_account_name>
- Password: Access key (available in ADLS account settings)
-
The storage account in MS Azure must be created with specific options. On the Advanced tab in storage account settings: In the Security section, Enable storage account key access must be checked; and in the Data Lake Storage Gen2 section, Enable hierarchical namespace must be checked.
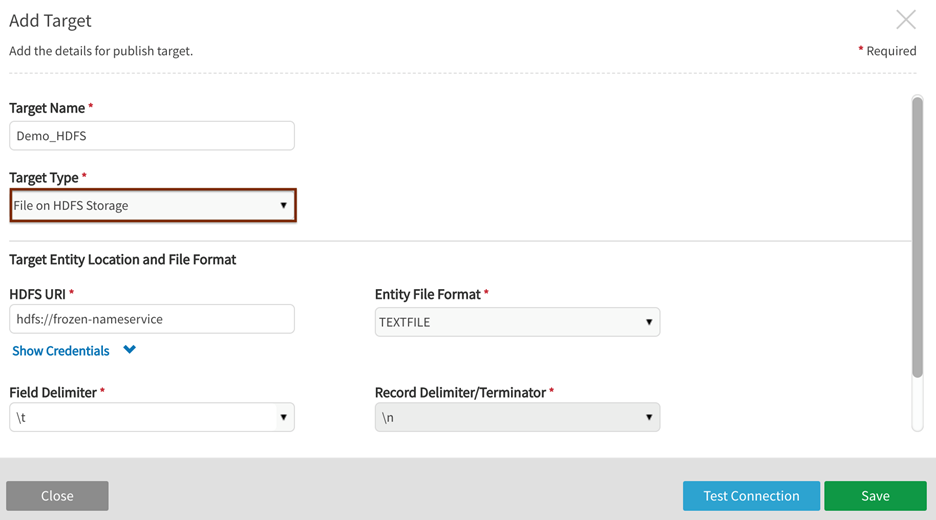
Add HADOOP – HDFS and Hive target
HADOOP – HDFS and Hive is the only publish target type requiring a Hive URI as Hadoop objects necessitate the creation of a Hive table on top of the HDFS file.
| Target format spec | Values |
|---|---|
|
Target Name |
user defined |
|
Target Type |
Hadoop – HDFS and Hive |
|
HDFS Target URI |
examples: hdfs://<localhost>:port/ hdfs://localhostname-nn-b.corp.podiumdata.com:8020/ |
|
Connection Credentials |
Optional, dependent on cluster security configuration |
|
HIVE Target URI |
examples: jdbc:hive2://domain.corp.mycompany.com:1000/default;principal=hive/domain.corp.mycompany.com@MYCOMPANY_SECURE.COM jdbc:hive2://m1.hdp.local:10010/<db>;principal=hive/_HOST@HDP.LOCAL
|
|
Connection Credentials |
Optional, dependent on cluster security configuration |
Example: Add Target for Hadoop-HDFS and Hive>
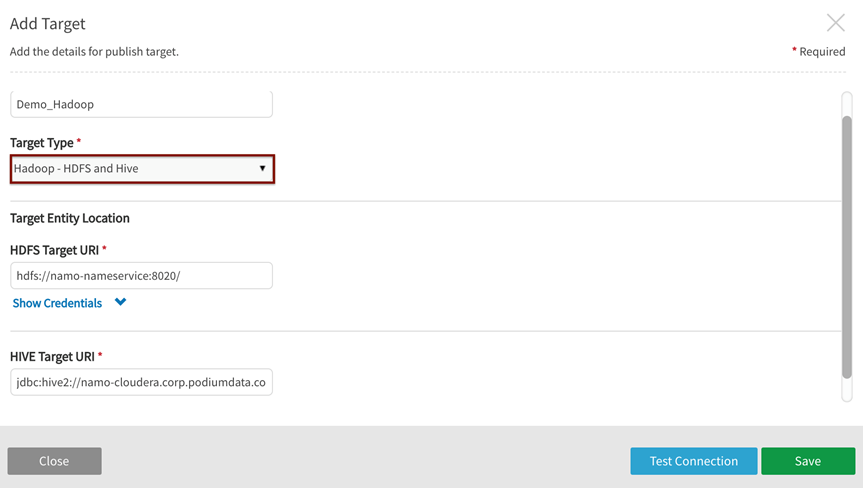
Add File on HDFS Storage target
Field Delimiter: \t
Record Terminator: \n
Header: none
| Target format spec | Values | ||||||
|---|---|---|---|---|---|---|---|
|
Target Name |
user defined |
||||||
|
Target Type |
HDFS (Hadoop Distributed File System) |
||||||
|
HDFS URI |
Examples: hdfs://<localhost>:port/ hdfs://localhostname-nn-b.corp.podiumdata.com:8020/ hdfs://192.168.128.23:8080/ |
||||||
|
Entity File Format |
Options: TEXTFILE: Flat file containing only printable characters (usually from ASCII char set) PARQUET: Columnar data format where data is stored and grouped in columns resulting in higher and more efficient compression ratios QVD: QlikView Data target format. Non-QVD entities can be converted and published as QVDs with this option. Note that if QVD file format is selected, the merge mode is restricted to MERGED. |
||||||
|
Field Delimiter |
Options*: (default) tab (\t) comma (,) pipe (|) semi-colon (;) colon (:) CTRL+A (\x01) space (\x20) double pipe (||) pipe tilde (|~)
|
||||||
|
Record Delimiter/Terminator |
Default: \n (Newline) |
||||||
|
Header (include field names?) |
Yes|No |
||||||
Example: Add Target for File on HDFS Storage
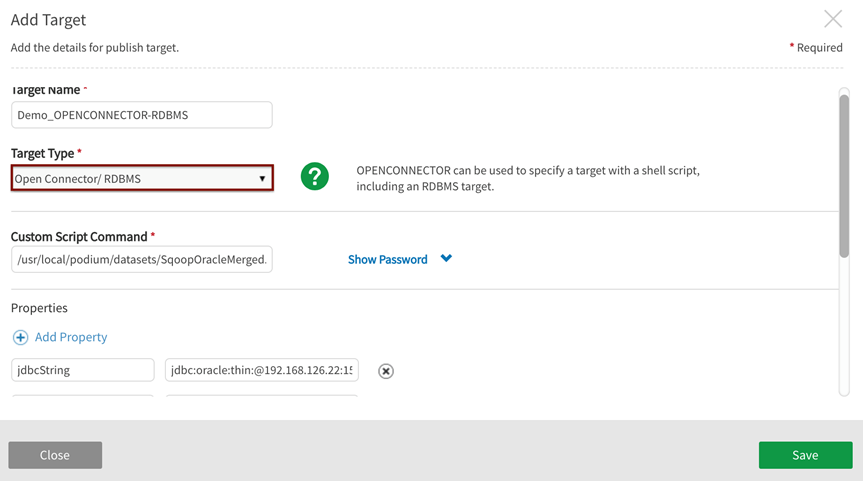
Add Open Connector/ RDBMS target
Open Connector/ RDBMS Target type replicates data from HDFS shipping location to RDBMS targets through Sqoop CLI tool. Sqoop provides a command line interface where users can provide basic information like source (Podium %shippingLocation), destination (%prop.jdbcString), table name (%prop.table) and any other authentication details (ex. %prop.username) required.
In addition to standard file based target specs, Open Connector targets require a Custom Script Command and the entry of argumentsto be passed through the command.
| Target format spec | Values | ||||||
|---|---|---|---|---|---|---|---|
|
Target Type |
Open Connector/ RDBMS |
||||||
|
Target Name |
user defined |
||||||
|
Custom Script Command |
Custom Script Command examples: /usr/local/podium/sqoopExport.sh %prop.jdbcString %prop.username %prop.table
%shippingLocation %loadingDockUri
/usr/local/podium/datasets/SqoopOracleMerged.sh %prop.jdbcString %prop.username %prop.table %shippingLocation
Note that 'shippingLocation' value is generated by Qlik Catalog and passed through the script. |
||||||
|
Password |
Optional, dependent on configuration |
||||||
|
Properties |
Add arguments to be passed via script. This step provides create, edit and over-ride options for Sqoop key/value pair properties. examples: property name: username property value: postgres |
||||||
|
Entity File Format |
Options: TEXTFILE: Flat File containing only printable characters (usually from ASCII char set) PARQUET: Columnar data format where data is stored/grouped in columns resulting in higher and more efficient compression ratios QVD: QlikView Data target format. Non-QVD entities can be converted and published as QVDs with this option. Note that if QVD file format is selected, the merge mode is restricted to MERGED. |
||||||
|
Field Delimiter |
Options*: (default) tab (\t) comma (,) pipe (|) semi-colon (;) colon (:) CTRL+A (\x01) space (\x20) double pipe (||) pipe tilde (|~)
|
||||||
|
Record Delimiter/Terminator |
Default: \n (Newline) |
||||||
|
Header (include field names?) |
Yes|No |
||||||
Save the Target.
Example: Add Target for (Open Connector/ RDBMS)
Bash SQOOP export script:
#!/bin/bash
#postgres
#jdbc:postgresql://<localhost>:5432/username
#postgres
#sqoop_export_test
#/podium-mydir/sqoopexporttest/sqoopExportTest.txt
set -x
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
jdbcString=$1
username=$2
table=$3
receivingDir=$4
additional=$5
read password
/usr/bin/sqoop export \
--verbose \
--connect "$jdbcString" \
--username "$username" \
--password "$password" \
--table $table \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--export-dir "$receivingDir/*" \
$additional
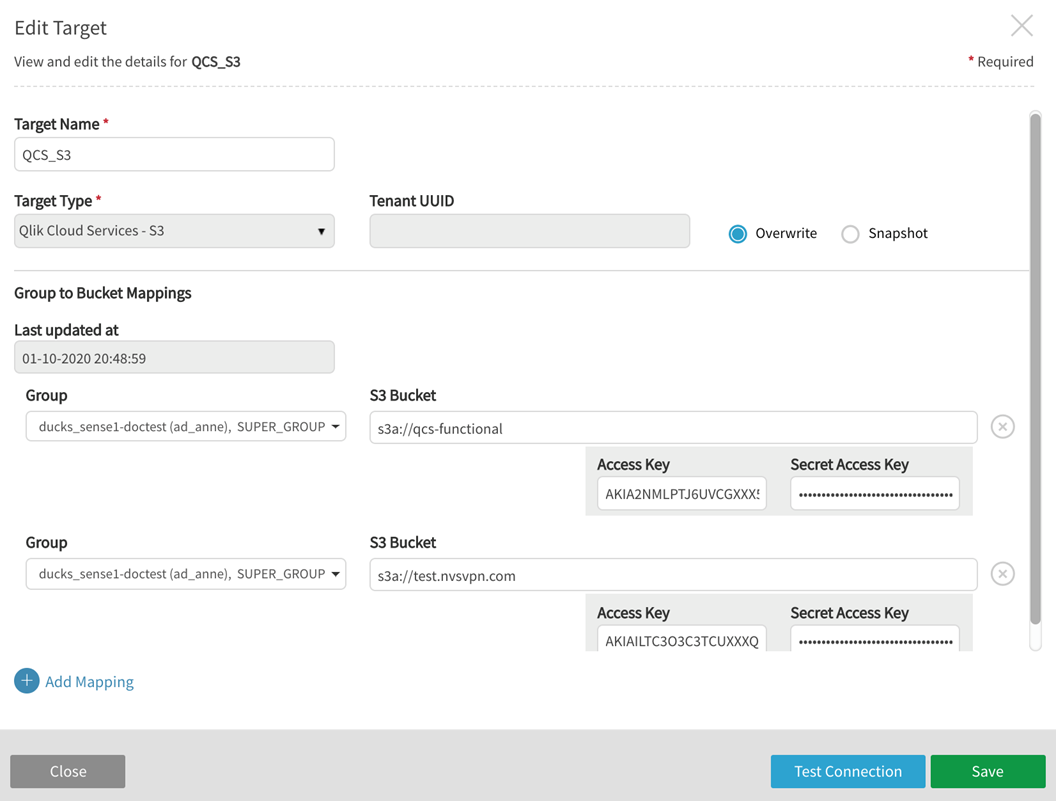
exit $?Add Qlik Cloud Services – S3 target
When setting up an Qlik Cloud publish target, users define the buckets accessible to Qlik Cloud with appropriate Access Key and Secret Access Keys.
| Target definition | Values |
|---|---|
|
Target Name |
user defined |
|
Target Type |
Qlik Cloud Services – S3 |
|
Tenant UUID |
[not in use currently -- reserved for future use] |
|
Overwrite/Snapshot |
Overwrite: App users who will always want to display the latest version of their data should choose this option. When "overwrite" is chosen, the folder takes on the following naming convention "QDC_sourceName_entityName" Snapshot: App users who would like to choose data from published "points in time" should choose this option. When Snapshot is chosen, a "sub-folder" is created, named with the addition of a timestamp: "QDC_sourceName_entityName/YYYY-MM-DD-hh-mm-ss" This structure can only be set at target definition time and cannot be changed afterwards. |
|
Group to Bucket Mappings |
|
|
Group |
These QVD and non-QVD groups will be given access to publish entities to specified S3 buckets If no groups are assigned to an S3 bucket, all groups will have access to that bucket A target can be created without groups or buckets; these can be edited at a later time to add groups and buckets. |
|
S3 Bucket |
examples: s3a://<host.name.com>/ s3a://test.nvsvpn.com/ s3a://qcs-functional NOTE: Scheme s3 should be used when Qlik Catalog is run in EMR (where it is maintained by AWS and is up-to-date). Scheme s3a should be used otherwise. Scheme s3n is obsolete and should not be used. |
|
Connection Credentials |
examples: Access Key: AKIAILTC3ORF95TGSSS5 Secret Access Key: kijf5tslHYJuykPPrVhhd0Tbj8RaHx8H3SfSSSv8 "Add Mapping" to provide credentials configuring additional S3 buckets |
Example: Edit Target for Qlik Cloud Services-S3