
Process new data incrementally
Incremental blocks will retrieve new and/or updated records in each automation run. These blocks can be used to process data incrementally in a scheduled automation. We call this polling
. This is the alternative to using a Triggered automation that uses Webhooks.
Incremental blocks have the benefit that they can be used to process historical data, something which is not possible with Webhooks.
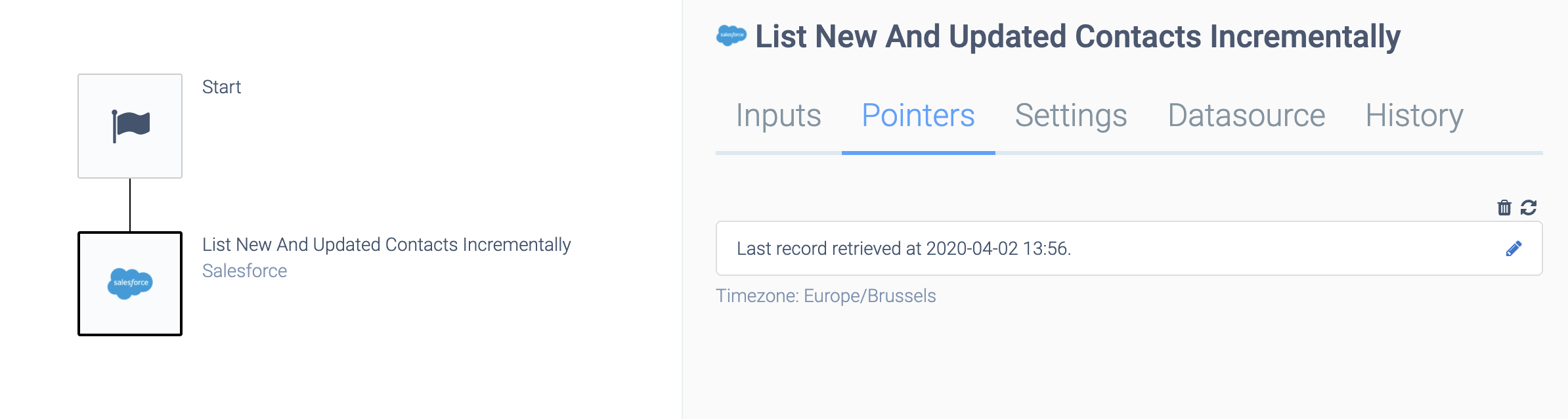
Incremental blocks keep an internal pointer. The pointer can be viewed and deleted or changed by clicking on the block, and selecting the Pointer tab in the pane on the right hand side:
Example of an Incremental block.
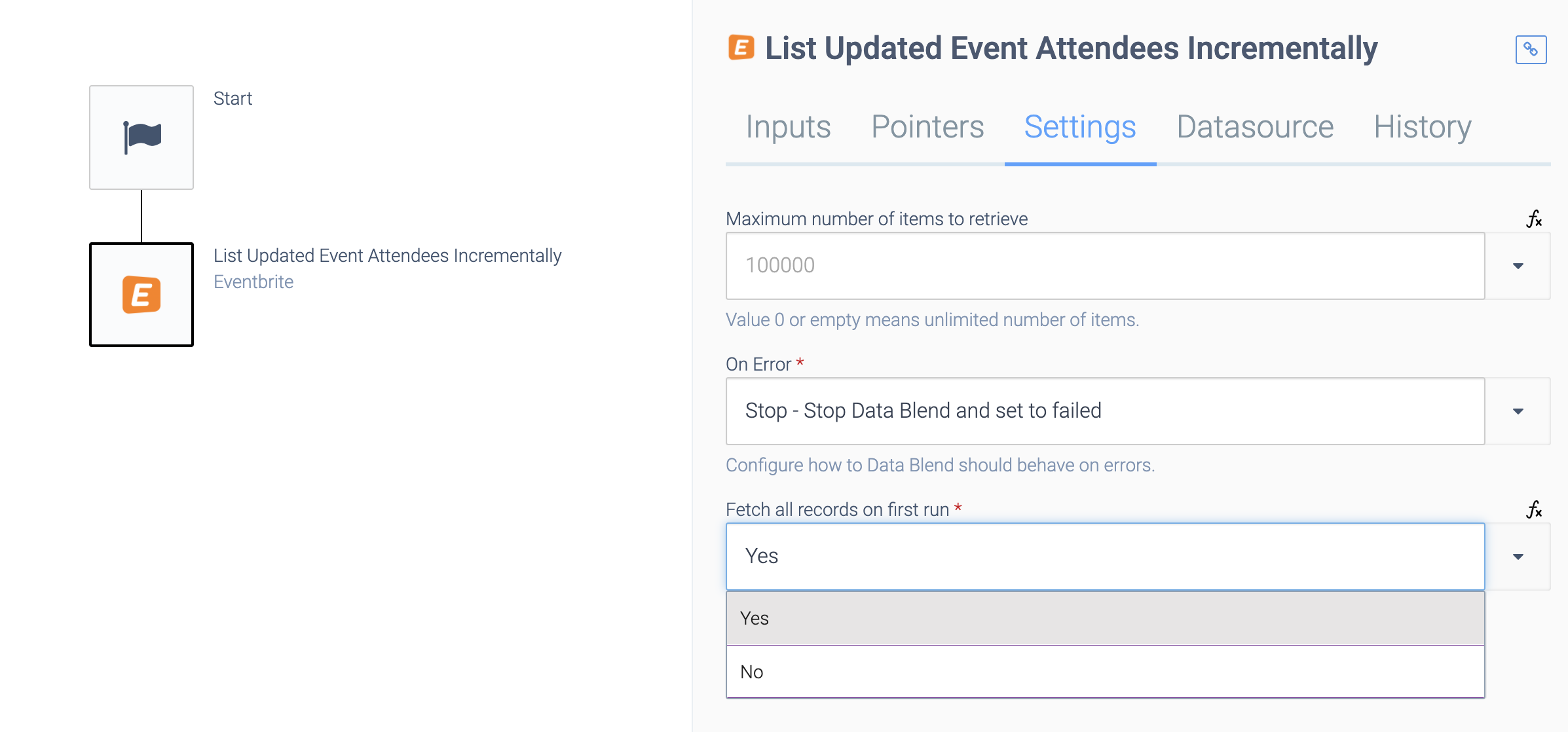
Under Settings, you can choose if the Block should fetch historical data on the first run yes/no:
Fetching historical data.
If you are testing an automation and the incremental Block does not return data, make sure to delete the pointer and run the automation again.
Uniqueness of the pointer
The pointer is unique for each combination of:
- automation
- Block type
- Block inputs
- Data source
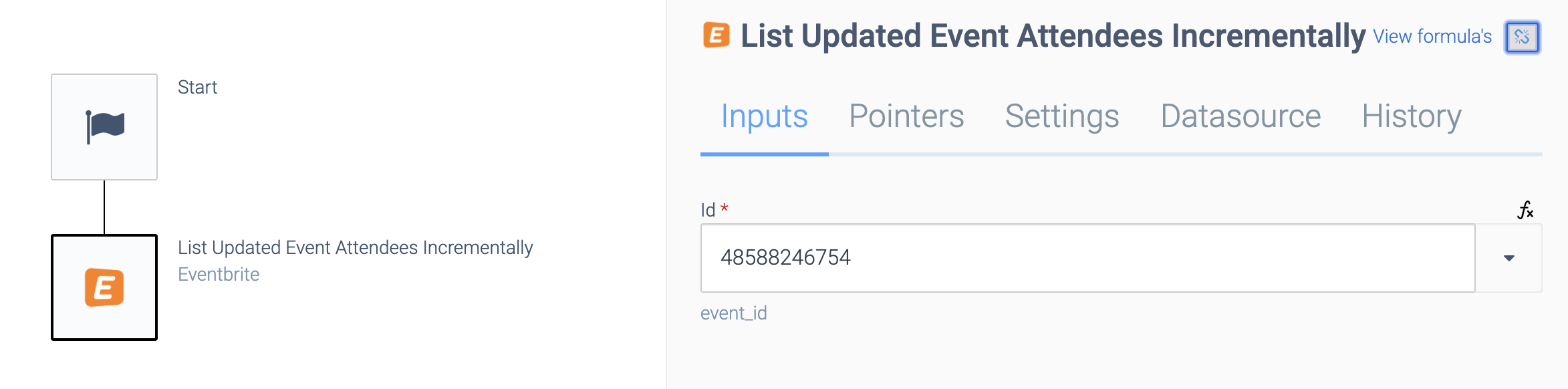
This means that if the incremental block has one input, a separate pointer will be kept for each input value. Example incremental block with one input:
An Incremental block with one input.
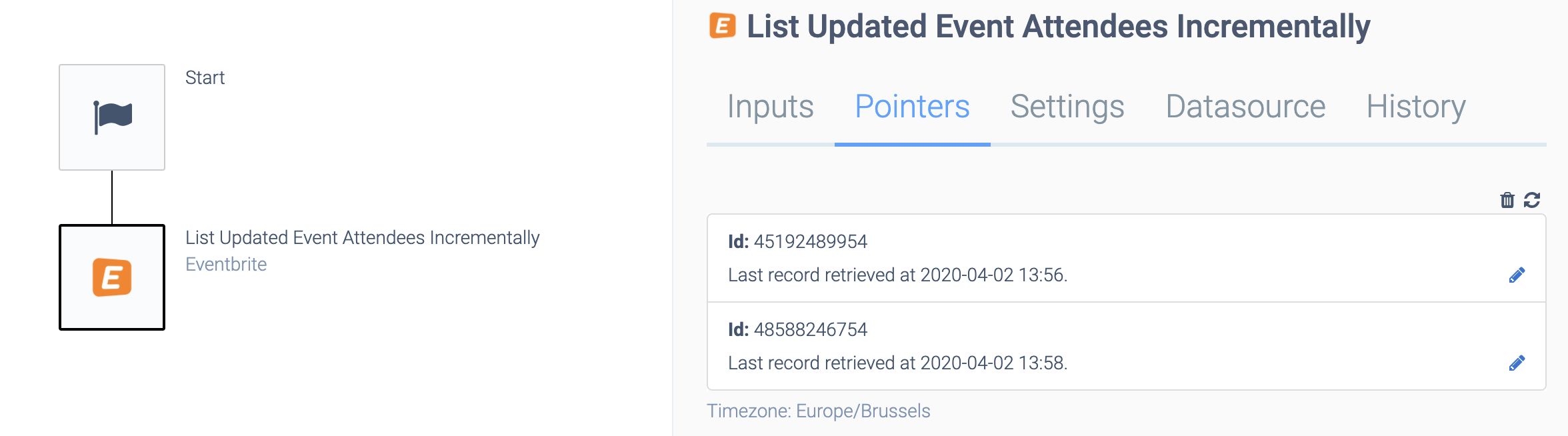
One pointer will be created for each input value that is used:
An Incremental block with two pointers.
The pointer is unique within each automation. Two automations with the same block will each have their own unique pointer.
If the same block is used twice in the same automation with the same inputs and same datasource, then these two blocks will share the same pointer.
When is the pointer increased?
The pointer will be increased on each run of the automation, if a successful response was received from the API (even if the response was empty).
If the API was down or did not respond with a 200 OK response code, the pointer will not be increased. This means that on the next run, the API call will be retried with the same pointer, so that you do not miss out on any data.
If the incremental endpoint received some data but the automation fails while looping over all the data, the pointer will still be increased.
Note that if the API is down, Qlik Application Automation for OEM will automatically retry for up to 5 minutes. This means that downtime of an API under 5 minutes will not cause any issues in your automation.
Related articles
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!